[算法导论笔记]建立二叉堆
本文共 1895 字,大约阅读时间需要 6 分钟。
二叉堆是基于数组的数据结构,由在数组上定义的left() right() parent()操作,以及heapsize属性,可以把它视为二叉树。
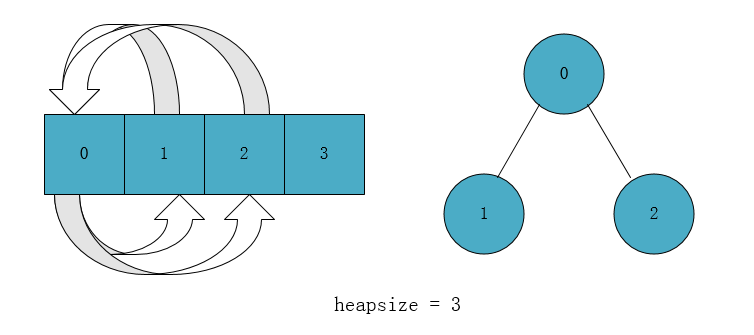 如图,根节点有两个叶子结点,分别对应的数组下标为1和2,通过left()和right()操作实现(下标位移再加偏移),而叶子结点的父节点通过parent()操作实现。由于此时的heapsize是3,因此数组中下标为3的第四个元素并没有加入堆中。
如图,根节点有两个叶子结点,分别对应的数组下标为1和2,通过left()和right()操作实现(下标位移再加偏移),而叶子结点的父节点通过parent()操作实现。由于此时的heapsize是3,因此数组中下标为3的第四个元素并没有加入堆中。 二叉堆分为最大堆和最小堆,最大堆的定义是,除了根节点以外的点 i 都要满足:A[parent(i)]>= A[i],换句话说,根节点必须大于等于子节点,如果最大堆完成。整个二叉堆就会呈现出每一层元素比下一层的元素要大,最大的元素就是根节点。因此,如果能建立出二叉堆,我们就能很快地获得其中的最大元素。而最小堆定义相反,不再赘述。
为了建立二叉堆,我们需要先有一个维护二叉堆性质的操作 heaplify(),它的作用对象是某个节点,对其进行检查,是否符合堆性质,如果符合就返回,不符合就修改(如最大堆,就是在子节点中找到最大的元素与父节点进行交换),再对进行修改过的子节点递归此操作。为了提高效率,我将尾递归改为了迭代。inline int prior(int l,int i,int r){ //依据性质找出最为优先的 if (l>=heap_size || r >= heap_size)return i; if (compare(l, i))i = l; if (compare(r, i))i = r; return i; } void heapify(int indx){ //堆维护 while (indx < heap_size / 2){ //只需对根节点维护 int temp = prior(left(indx), indx, right(indx)); if (temp == indx)break; else swap(data[indx], data[temp]); indx = temp; } } 假设最好情况,heaplify只需要常数时间(indx结点无需维护),而考虑最坏情况,indx每次都要移动直至叶子结点。因此时间复杂度为O(n),n为初始indx的结点规模。
严谨的方法则是使用递归式对运行时间进行刻画:我们只需要保证数组中每个元素都满足堆性质,就可以建成一个二叉堆。虽然有了维护堆的方法,但我们不必对每个元素都进行维护。理由是叶节点无需维护,只有根节点才需要。
所以从每个叶节点开始,递归对其父节点执行堆维护heaplify()操作,直到根节点。一共进行n/2次heaplify()操作,因为堆维护的复杂度为O(lgn),所以一个不是渐进紧确的复杂度估计是O(nlogn)。void build(){ //建堆 heap_size = data.size(); for (int i = heap_size / 2 - 1; i >= 0; i--) heapify(i); } 但是这里存在一个问题,堆维护的复杂度与树高有关系,而建堆过程中,高度是逐层上升,而每层需要维护的结点数也是越来越少的。对于高度为h的结点,堆维护只需要O(h)时间。
因此一共用时:
∑hi=0ni∗O(i) 其中 ni 为高度为 i 的堆包含的结点数,可以求出: ni≥n/2i+1 代入得: ∑hi=0n/2i+1∗O(i)=∑hi=0O(n∗i/2i) 由级数的知识对i求极限可得时间复杂度上界为 O(n)详细的证明过程可见原书,这里只指出大概的思想以及两个小细节(在原书是证明题):结点数为n的堆高度为最多是lgn,高度为h的堆结点数最多是 n/2h+1
第一个:如果是满二叉树,结点一共 n=2h 个,因此堆高最多 lgn ;如果不是满二叉树,结点数 n<2h ,高度为lgn向下取整。 第二个:如果是满二叉树,从底层往上每一层元素为 2lgn−h ,h为该层高度,所以高度为h的堆包含结点数为: ∑hi=02lgn−i=∑hi=0n(1/2)i ,等比数列求和得出结果为: n/2h+1 .如果不是满二叉树方法同上,结果是 n/2h+1 向上取整。
你可能感兴趣的文章
必学高级SQL语句
查看>>
经典SQL语句大全
查看>>
Eclipse快捷键 10个最有用的快捷键
查看>>
log日志记录是什么
查看>>
<rich:modelPanel>标签的使用
查看>>
<h:commandLink>和<h:inputLink>的区别
查看>>
<a4j:keeyAlive>的英文介绍
查看>>
关于list对象的转化问题
查看>>
VOPO对象介绍
查看>>
suse创建的虚拟机,修改ip地址
查看>>
linux的挂载的问题,重启后就挂载就没有了
查看>>
docker原始镜像启动容器并创建Apache服务器实现反向代理
查看>>
docker容器秒死的解决办法
查看>>
管理网&业务网的一些笔记
查看>>
openstack报错解决一
查看>>
openstack报错解决二
查看>>
linux source命令
查看>>
openstack报错解决三
查看>>
乙未年年终总结
查看>>
子网掩码
查看>>